
如今,來自加州大學默塞德分校的 Xueqing Deng 團隊解決了這一問題。他們訓練了一種機器學習演算法,在觀察衛星圖片後,就可以生成地面視角的圖片。
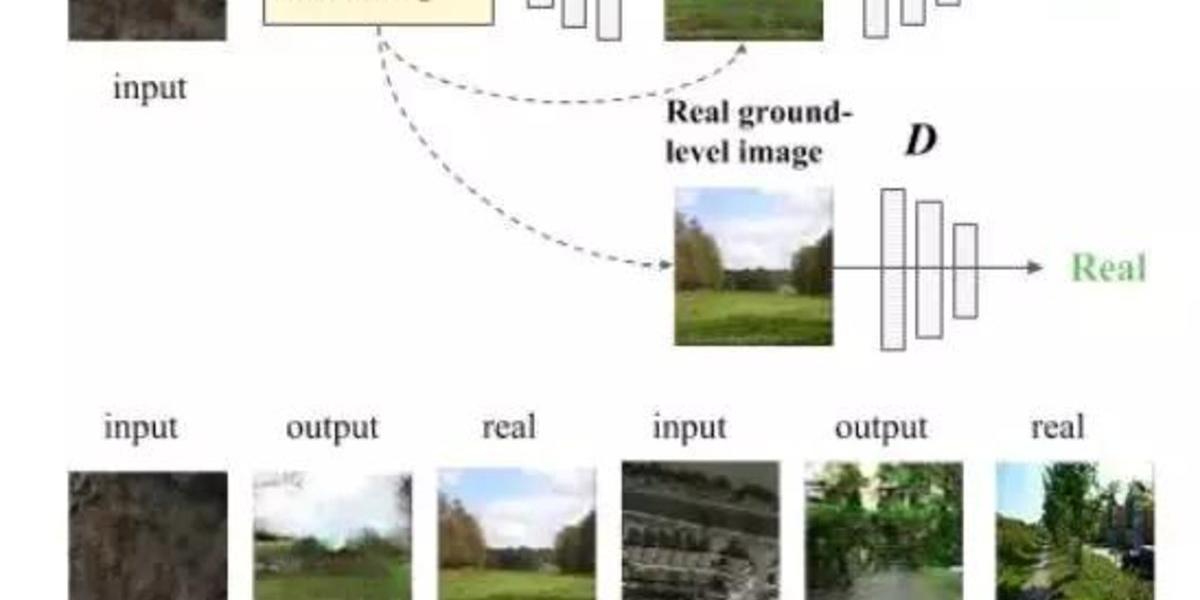
這項技術基於一種叫做生成對抗網路的模型,這種模型由兩大模組組成,一種叫做生成器,另一種叫做判別器。

以生成長頸鹿的圖片為例,生成器先生成一張圖像,判別器基於一些學習準則進行評估,比如評估它們與長頸鹿的相似程度,生成器接收判別器回饋的評估結果進行修正。重複這段過程,生成器就能逐漸學會產生像長頸鹿一樣的圖像。
類似上述例子,Deng 的團隊使用地面角度的真實圖像和對應區域的衛星圖像來訓練判別器,這樣判別器就會學會如何將衛星圖像與對應區域的地面圖像關聯起來。
當然,資料集的品質同樣重要。Deng 的團隊使用的是 LCM2015 地面覆蓋圖,涵蓋整個英國, 解析度達到 1 公里。不過,該團隊只運用了包括倫敦和周邊鄉村在內的 71x71 公里的網格上的數據。他們從一個叫做 Geograph 的線上資料庫,下載了網格中的每個位置相應的地面圖像。
接下來,該研究團隊使用 16000 對衛星圖像和地面圖像對判別器進行了訓練。
下一步就是生成地面圖片了。他們把特定位置的一組 4000 張衛星圖像輸入到生成器,並結合判別器的回饋結果,生成器為每個衛星圖像創建了相應位置的地面視圖。隨後研究團隊利用 4000 張衛星圖像作為測試資料,把這 4000 張衛星圖像經生成器生成的地面圖片與真實圖片進行比較。
結果非常有趣。如果對圖像品質要求不太高的話,網路會產生比較合理的圖像。該模型生成的圖像捕捉到了一些地面的基本特徵,比如某個位置是不是一條路,或者區分出某個區域是農村還是城市等等。「生成的地面圖像儘管看起來比較自然,但是正如預期的那樣,缺乏真實圖片的細節。」Deng 和他的團隊說。
這一工作很漂亮,但究竟會有多大作用?地理學家的一項重要任務就是根據土地的用途對土地進行分類,比如,某片土地是農村還是城市。
地面角度的圖像就對這項任務非常重要,但是這類資料非常稀缺,尤其是對非城市地區。目前地理學家一般利用插值技術,在圖像之間進行插值,結果僅比隨機猜測好一點。
現在 Deng 的團隊所使用的這項生成對抗網路技術給地理學家們提供了新的方法。當地理學家想知道某個區域的地面視角的圖像,他們只需要找到對應位置的衛星圖像,利用這種方法生成一些地面視圖就可以了。
Deng 的團隊比較了插值方法和圖像生成方法的結果。這種圖像生成的技術最終正確判別了 73% 的土地使用情況,而插值方法的正確率只有 65%。
這是一項很有趣的工作,能夠大大減輕地理學家的工作量。不過 Deng 和他的團隊有著更大的野心。他們希望進一步改進圖像生成過程,以期在未來能夠在生成的圖片中提供更多的細節特徵。即使達文西本人也會對這項技術欽佩的。