
據科技媒體Science News報導,全球多個科研團隊已在研發可自動識別新聞真偽的程式。它們的主要功能是對新聞的可信度做一個初步的鑑定,並將結果傳遞給讀者以供其參考。
印第安那大學布魯明頓分校的電腦科學家Giovanni Luca Ciampaglia表示,業內對這種鑑定演算法的開發目前普遍處於起步階段,對於一篇報導,選取哪些因素作為判定其可信度的方法也是五花八門。
不過這些程式對一則新聞的關注點大致可分為2類:報導的內容和敘述的口吻。
上文提到的Ciampaglia和他的科研團隊就著眼於報導的主要觀點,主語和賓語間的聯繫有無客觀事實支撐。他們的演算法收納了大量Wikipedia詞條頁面的右側資訊欄(「Infobox」)中的資訊,並將主詞條與所有副詞條配對,形成一個以名詞及名詞間聯繫為主的資料庫。如果一篇報導的主要觀點中,主語與後面的描述性名詞之間的聯繫能在該資料庫中以較短路徑追溯到,那麼這條新聞的主旨就相對可信。
比如「歐巴馬是個穆斯林」這句話中,「歐巴馬」和「穆斯林」之間存在7重聯繫,也就是說在資料庫中需要跨越7組名詞間的兩兩配對才能將這2個詞扯在一起,這說明該言論是不太靠得住的。

但這種基於名詞間關聯強度的判定方法也有一定局限性。比如,它無法判定「George W. Bush(小布希)娶了Barbara Bush(芭芭拉·布希,小布希老媽)」這句話的真偽,因為在資料庫中這2個名詞高度相關。因此Ciampaglia也正設法為他的演算法添加其他參數以提升其合理性。
美國倫斯勒理工大學的電腦科學家Benjamin Horne和Sibel Adali則提出了另一個方法。他們分析了由Business Insider評定的最值得信賴媒體發布的75篇真實報導,以及網上公認的75篇偽新聞,隨後總結出:假新聞通常篇幅比真的短,會重複性地出現許多副詞,其中的引述和專業詞彙也相對更少。
他們由此建立了一套以文章所含名詞數量、引述數量、冗長度以及總字數為參數的評定演算法。該演算法曾在去年於加拿大蒙特利爾舉行的網路與社會媒體國際研討會(International Conference on Web and Social Media)上做現場演示,並在辨別假新聞時準確率達到了71%。
密西根大學安娜堡分校的電腦科學家Verónica Pérez-Rosas同樣發現假新聞中的副詞使用頻次要高於真新聞。在2017年8月發布於科學文獻資料庫arXiv.org的研究報告中,Pérez-Rosas也提出,假新聞會使用更多正面措辭,並且更喜歡下結論。
由此可見,假新聞在寫作手法上有共通之處。加州大學河濱分校的電腦科學家Vagelis Papalexakis就根據2篇報導間的行文相似度來判定它們的真偽。雖然他在研究報告中並未明確列出衡量相似度的具體參數,但在包含真假新聞各32,000個的資料庫中,他的演算法能在預知其中5%的文章哪些是真哪些是假的情況下,以69%的準確率判定出其他文章的真偽。
社交網站可以用這些演算法來給新聞做初步檢查,並在用戶打開一篇疑似假新聞時,給用戶發一個預警提示。比如目前Facebook就會在後台監測哪些新聞下多了質疑性評論,然後專業人員會對這些新聞做出評定,並將評定結果錄入Facebook原先的自動鑑別演算法所用資料庫中,從而實現演算法的優化。
英國帝國理工學院的電腦科學家Julio Amador Diaz Lopez表示,即使目前這些鑑定演算法演化得越來越「聰明」,但面對背景較抽象,如宗教、哲學等方面的報導,程式可能還是無法像人類一樣會意,或辨識其可信度。同時,如果從寫作風格著手的鑑偽程式被廣泛採用,那原先假新聞的作者也會適當地改變自己的寫作手法以圖蒙混過關。
幸好,目前業內已出現了不只關注文字本身的演算法。中國科學院計算技術研究所的曹娟提出的演算法就著眼於讀者的回饋模式。她將微博上用戶對新聞的觀點分為支持和反對2類。比如對於一條地方新聞,地理位置更接近事發地點的用戶做出的評論,就比相距較遠的讀者的回饋更具可信度。再比如一個隱身很久但突然冒出來給一條新聞評論的用戶,他的言論可信度也就較低。
曹娟的團隊選取了微博上傳播的真偽新聞各73條,他們的演算法通過分析這些新聞下共約5萬條持支持或反對意見的評論,最終以84%的正確率識別出了假新聞。該研究成果也曾在的美國人工智慧進步協會(Association for the Advancement of Artificial Intelligence)2016年大會上展出。
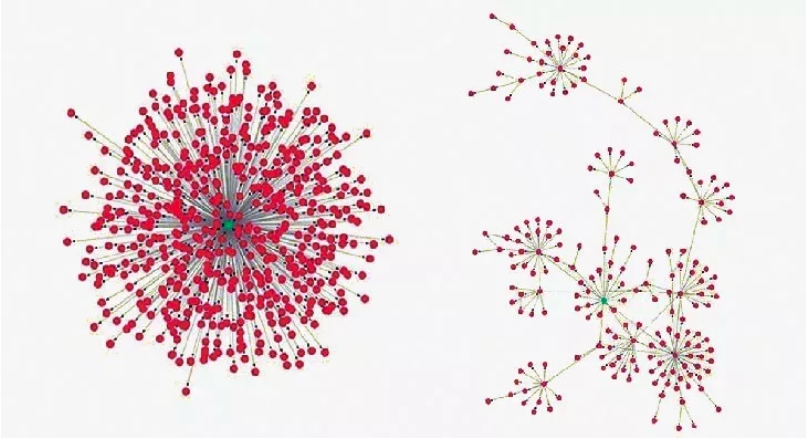
同樣,來自北京航空航太大學的網路專家李大慶教授也未把內容作為鑑偽程式的重心,而是把新聞的傳播形式當作主要評判依據。他收集了微博上1,700條假新聞、500條真新聞,以及推特上真假新聞各30條,分析了它們的擴散特徵後發現,真新聞的傳播主要是靠用戶從單個可靠訊息源的直接分享,而假新聞的傳播則主要依託用戶間的分享。
再回到這些演算法的實際應用——社交網站現階段還不宜單單依據演算法判斷的結果,將所有疑似假新聞一律遮罩,這樣相當於以極權主義干涉了使用者自主選擇流覽資訊的權利。Facebook目前的做法是將系統鑑定出的低可信度報導自動置於推送欄底部,據公司發言人Svensson表示,這樣可以將虛假新聞的閱讀量減少約80%。另外,前文提到的根據初步鑑定結果給使用者發警示消息,也可能成為未來社交網站上對此類演算法的應用形式之一。
本文係由DeepTech深科技授權刊登。原文連結: 揭秘AI识别虚假新闻背后的原理